Dashboard Cost Estimates
The Vapi dashboard provides static cost projections on a per-assistant basis, so you can get a rough idea of the costs your assistant will incur during live execution.
Calling Your Assistant
One good way to get an empirical per-minute cost on your whole voice pipeline is to actually call in, use it for a few minutes, & observe the average cost/minute at the call level.You can view a breakdown of your cost per call in your dashboard at
dashboard.vapi.ai/calls
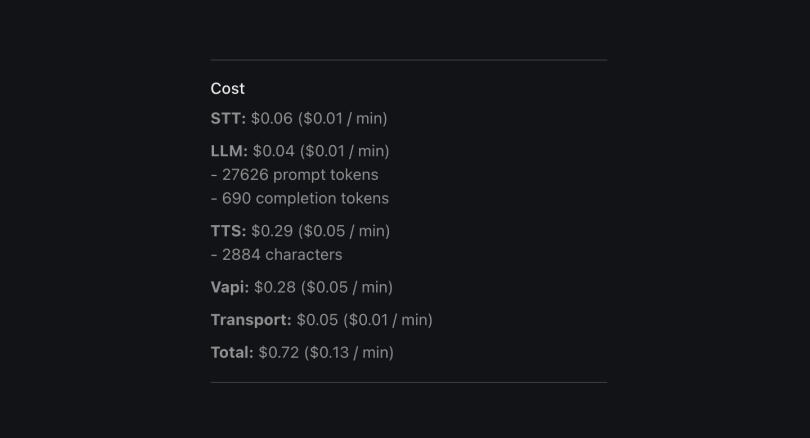
STT: Speech-to-text (providers often bill per-minute, prorated)LLM: LLM inference (providers often bill per-million or per-thousand tokens)TTS: Text-to-speech (providers often bill per-character)Vapi: the Vapi platform fee of 5¢/minute (prorated per-second)Transport: telephony costs (incurred for inbound/outbound phone calls to/from a phone number) (providers often bill per-minute)
General Provider Estimates
The provider costs listed below are subject to change as we get more data, but they will always reflect our best estimate of the provider costs per minute:Speech-to-text Provider Estimates (Transcription)
Speech-to-text Provider Estimates (Transcription)
Speech-to-text Provider
Deepgram: $0.01/min (=$0.60/hr)
Model Provider Estimates
Model Provider Estimates
Model Provider
- OpenAI (gpt-4-turbo): $0.20/min (=$12.00/hr)
OpenAI (gpt-3.5-turbo): $0.02/min (=$1.20/hr)
Voice Provider Estimates
Voice Provider Estimates
Voice Provider
- ElevenLabs: $0.04/min (=$2.40/hr)
PlayHT: $0.07/min (=$4.20/hr)
Deepgram: $0.02/min (=$1.20/hr)
OpenAI: $0.02/min (=$1.20/hr)
RimeAI: $0.03/min (=$1.80/hr)
Azure: $0.02/min (=$1.20/hr)
Neets: $0.005/min (=$0.30/hr)
LMNT: $0.03/min (=$1.80/hr)