When a person speaks, the client device (whether it is a laptop, phone, etc) will record raw
audio (1’s & 0’s at the core of it).
This raw audio will have to either be transcribed on the client device itself, or get shipped
off to a server somewhere to turn into transcription text.
That transcript text will then get fed into a prompt & run through an LLM ([LLM
inference](/glossary#inference)). The LLM is the core intelligence that simulates a person
behind-the-scenes.
The LLM outputs text that now must be spoken. That text is turned back into raw audio (again,
1’s & 0’s), that is playable back at the user’s device.
This process can also either happen on the user’s device itself, or on a server somewhere
(then the raw speech audio be shipped back to the user).
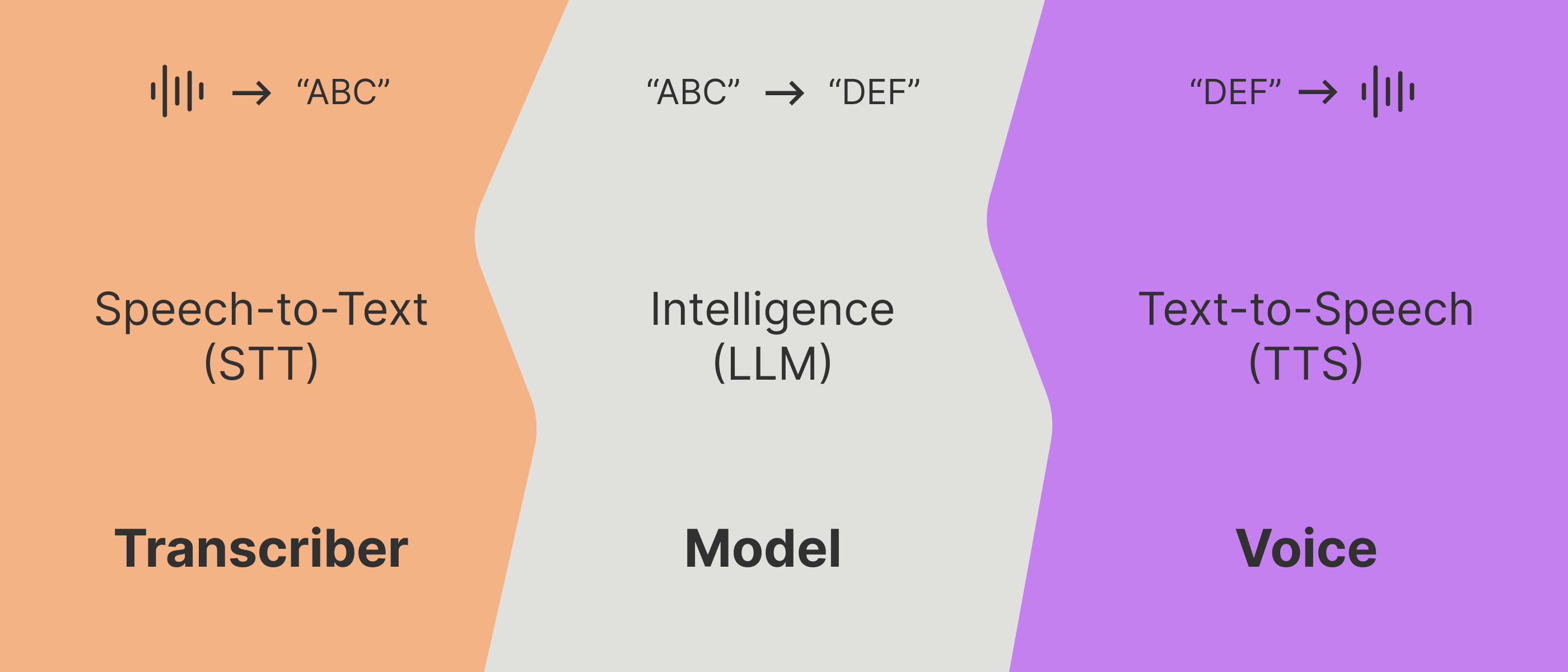 ## The 3 Phases
To get you started as quickly as possible, we're going to narrow down & focus on the 3 key concepts of Vapi voice assistants: the **transcriber**, the **model**, & the **voice**.
## The 3 Phases
To get you started as quickly as possible, we're going to narrow down & focus on the 3 key concepts of Vapi voice assistants: the **transcriber**, the **model**, & the **voice**.
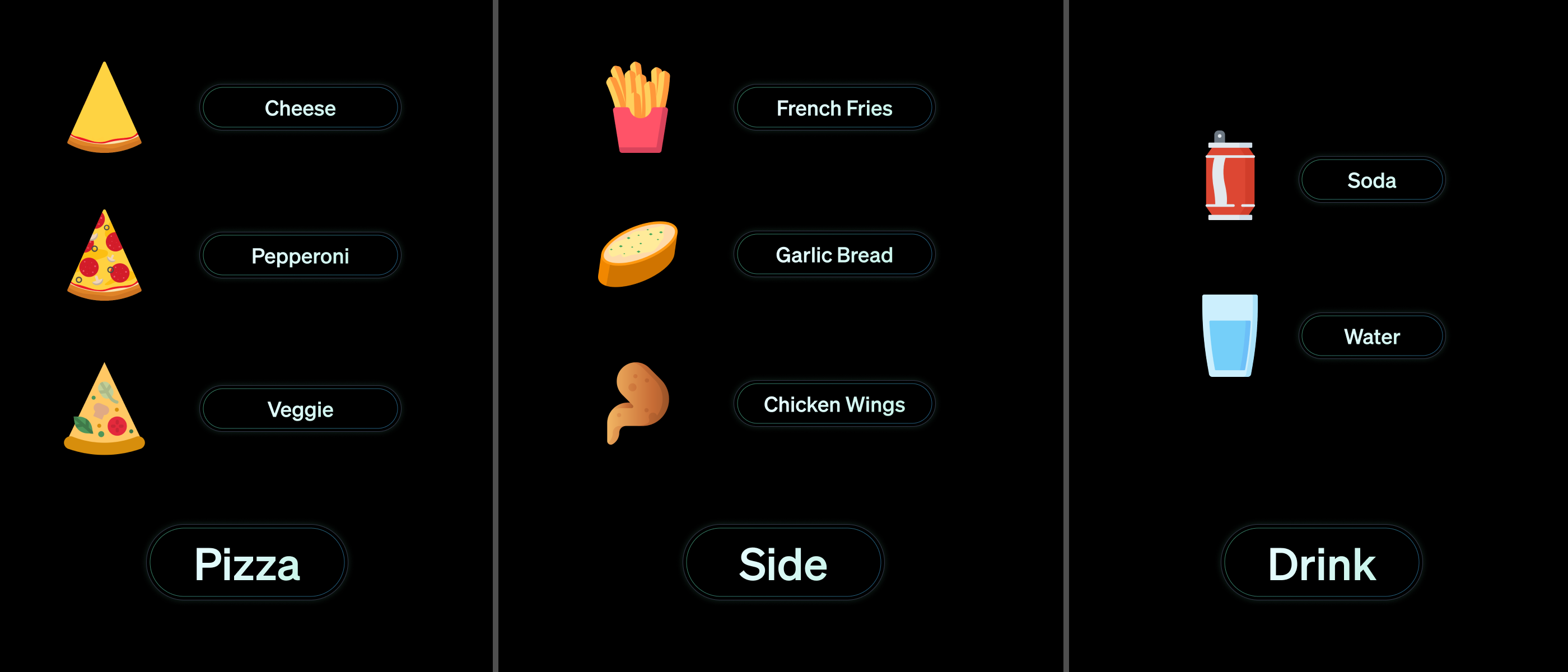 We will walk through the same quickstart demo with every major way you can integrate & interface with Vapi’s systems:
We will walk through the same quickstart demo with every major way you can integrate & interface with Vapi’s systems: